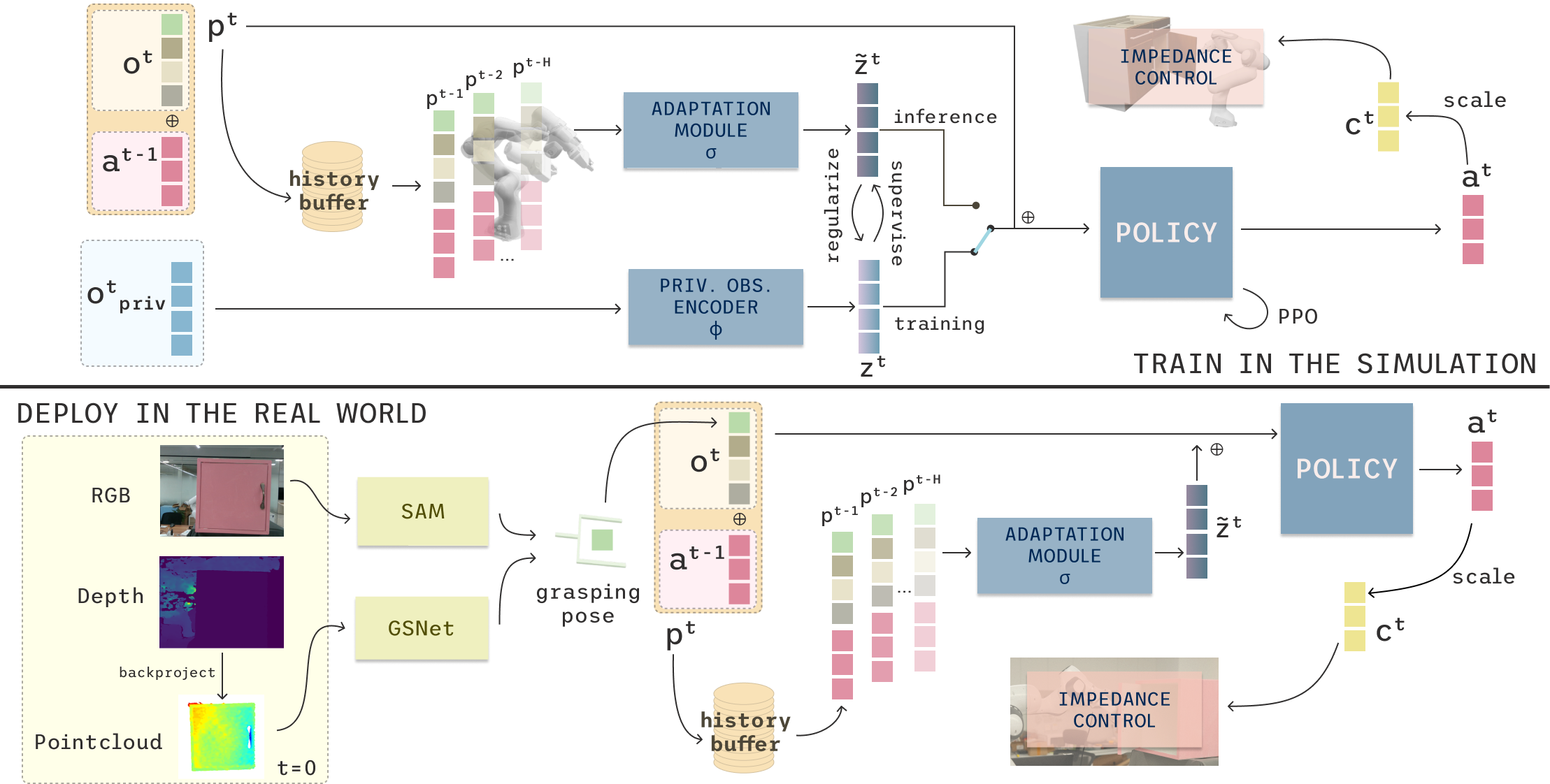
Why articulated object manipulation is hard?
- To safely open a door, you need to understand its articulation motion. This includes object weight, friction, pivot radius,... which we only know after interacting with the object
- Therefore, using open-loop pipeline or predicting the action waypoint before-hand is not enough
- Ok let's say we have a constant visual feedback of during manipulation, will it help? You're now pretty sure that you grasped the door handle or even have it opened a bit. But the large vision sim2real gap makes it hard to generalize.
- One more thing, this handle might be occluded in while opening, meaning that you have to find a good viewpoint to really capture things you need. Again not really generalizable.